
Branching Directive - A Unified Approach to Research Management
In the realm of artificial intelligence and knowledge management, we often find ourselves grappling with fundamental questions about the nature of understanding and the structure of knowledge. As Voltaire wisely counseled, “We must cultivate our own garden.” This philosophy has been a guiding principle in the development of the Branching Directive, a novel system that seeks to bridge the gap between human cognition and artificial intelligence.
Philosophical Roots
To understand the motivation behind this project, we must first set the context with some deeper philosophical concepts. Ruth Millikan’s treatment of Donald Davidson’s “Swampman” thought experiment challenges our notions of identity and meaning. Imagine a machine that could assemble atoms to create an exact physical duplicate of a person, including their brain state. This clone, the Swampman, would be molecule-for-molecule identical to the original person at the moment of creation.
Yet, Millikan argues, this Swampman would lack genuine thoughts, intentions, or semantic content. Why? Because it lacks the appropriate history. This idea hinges on Millikan’s concept of “proper function” - the notion that the meaning and function of our thoughts and behaviors are determined by their evolutionary and personal history.
Building on this foundation, Millikan introduced the concepts of “unitrackers” and “unicepts.” A unitracker is akin to a pattern recognition system, allowing us to track and identify recurring elements in our environment. A unicept, on the other hand, is a unified concept that integrates various instances and aspects of a thing across different contexts.
These ideas resonate deeply with the challenge we face in artificial intelligence. Current AI systems excel at unitracking - pattern recognition - but struggle with forming true unicepts, those unified, context-dependent concepts that can be flexibly applied across different situations.
The Branching Directive: A Novel Approach
Recognizing this challenge, the Branching Directive represents an experimental system that automates and self-organizes research using large language models (LLMs) within a graph-based document structure. It’s an attempt to cultivate our own garden of knowledge, one that grows and evolves through a combination of human insight and AI processing.

Full visualization of the research tree, showcasing the scale and interconnectedness of the knowledge base.
Key Features:
- Unified Tree Structure: The system employs a tree-based architecture across multiple domains:
- Document Management: Research entries form a hierarchical graph, allowing for flexible knowledge organization.
- Code Edits: A tree-based representation of code structures enables precise modifications and refactoring.
- Conversation Management: Dialogues with the LLM are structured as conversation trees, preserving context and allowing for branching discussions.
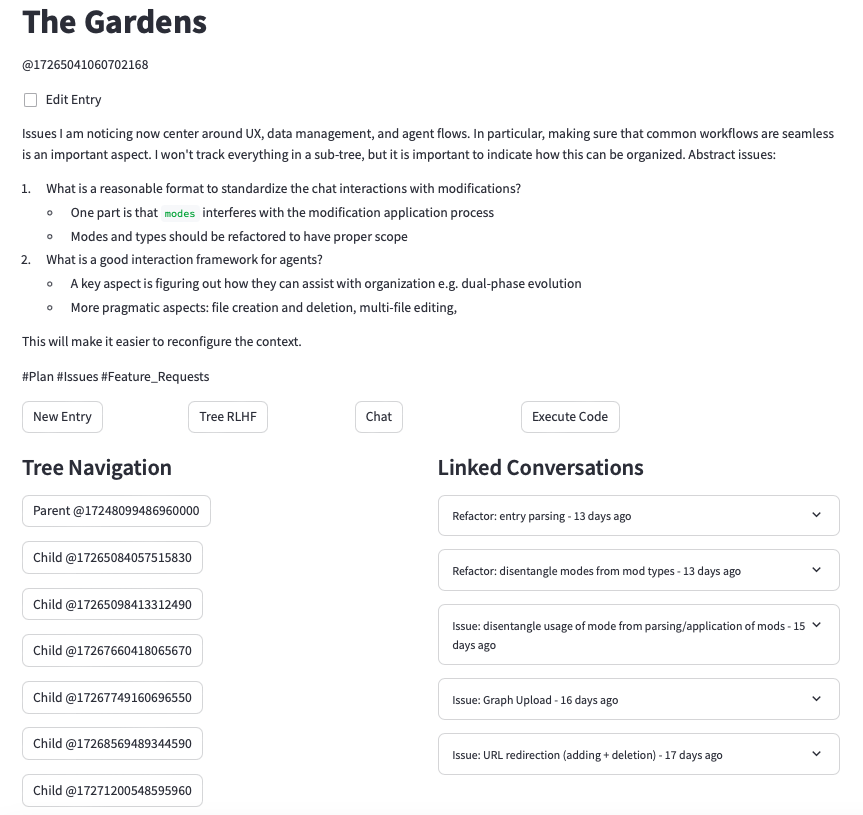
Screenshot of an entry. This entry is the root of a sub-tree managing various issues with the system. At the bottom left you can see links to more detailed descriptions of issues and the bottom right shows linked conversations for easily resolved issues.
- Massive Personal Knowledge Base: The system currently manages a personal document collection of approximately 4 million tokens, demonstrating its capability to handle large-scale, long-term research projects.
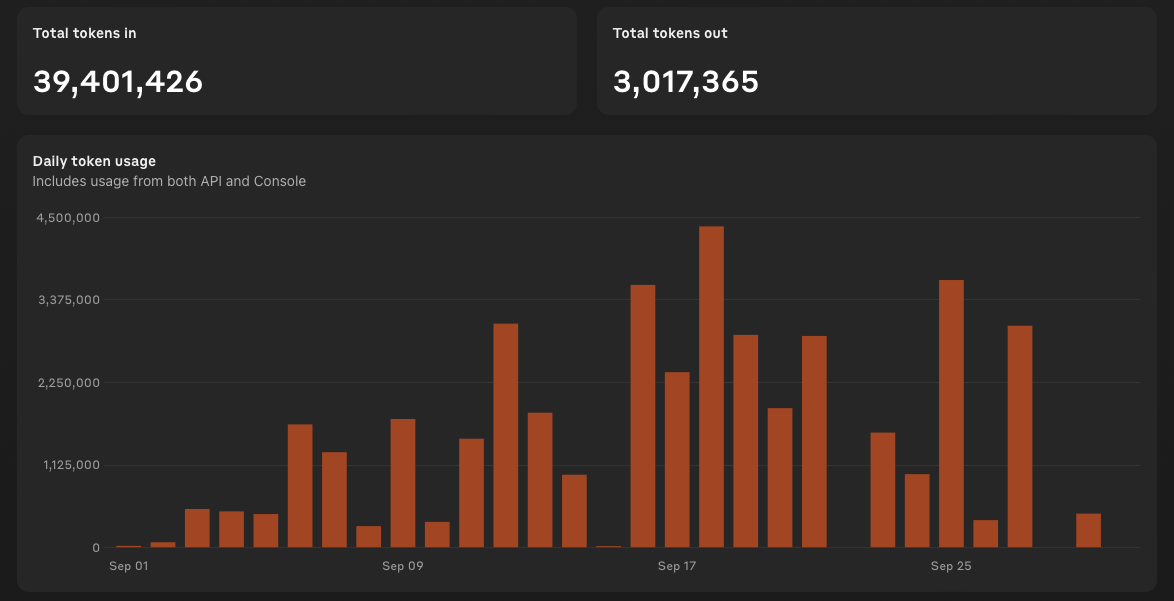
Graph showing the attention (token usage) over a one-month period, highlighting periods of intense research activity.
- Interactive Interface: A responsive interface built with Streamlit lets users explore and expand the document tree, viewing the relationships between different entries.

Detailed view of an entry, showing its content, parent and child relationships, and the overall sub-tree.
-
Self-Growth through LLMs: The system allows LLMs to autonomously expand the graph by adding new entries based on existing nodes, creating a constantly evolving repository of insights and ideas.
-
Code Modification and Execution: Integrated features for modifying and executing code directly within the research environment, bridging the gap between theoretical concepts and practical implementation.
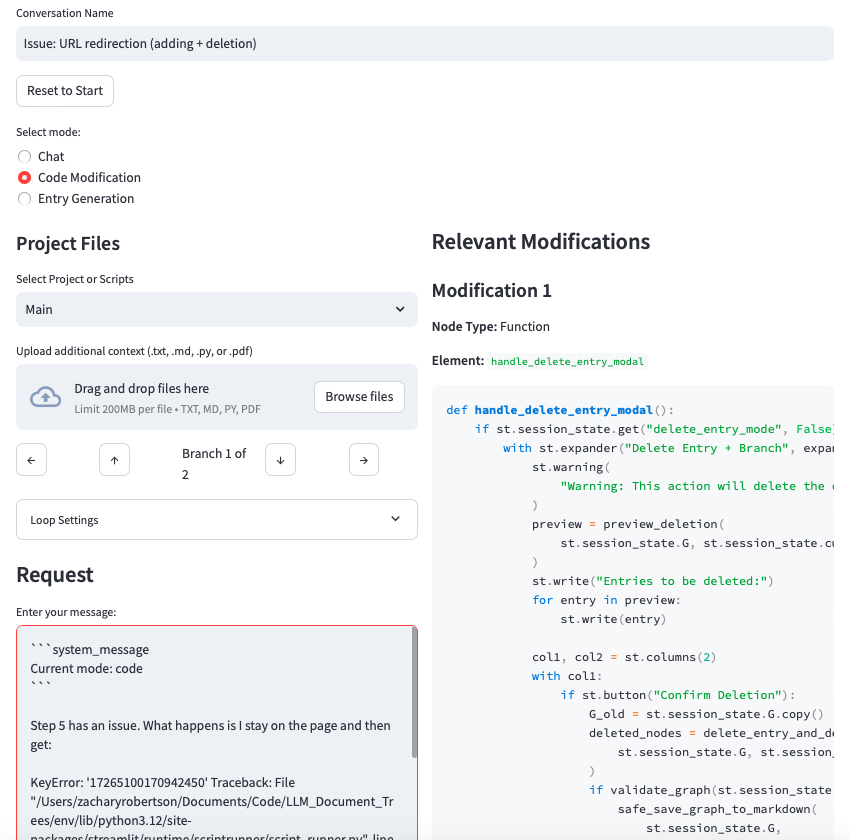
The code editing interface, showcasing real-time modifications and their effects.
Implications and Future Directions
The implications of this approach are far-reaching. It could inform the development of more sophisticated AI systems that can form and manipulate concepts in more human-like ways. It might help in managing large-scale research projects, providing a framework for organizing and connecting diverse ideas. And it could offer new insights into human cognition, helping us understand how we form and use complex, context-dependent concepts.
As we continue to develop and refine this system, we’re mindful of Voltaire’s wisdom. We’re cultivating our own garden of knowledge, nurturing it with a combination of human insight and AI capabilities. This garden is not just a collection of information, but a living, growing ecosystem of ideas that evolves and adapts over time.
Why Share?
While we’re not sharing the specifics of our “garden” at this time - the actual data and code behind the Branching Directive - we believe that the principles and approach we’re developing could have broad implications for how we manage knowledge and conduct research in the age of AI.
As we move forward, we invite you to consider: How might this unified approach to research management, combining document organization, code development, and LLM-driven exploration, resonate with your projects or lead to new ways of working with LLMs? Could this be a step towards creating AI systems that can truly understand and reason, rather than just recognize patterns?
In the spirit of Voltaire, let us all continue to cultivate our gardens of knowledge, always striving to grow, adapt, and understand the world around us in deeper and more meaningful ways.