
Calculating the Quran
Can the Quran be analyzed algorithmically? Many would say no. The Quran is a large and sophisticated document that does not yield to the reductionist approaches traditionally found in statistical sciences. However, a reduction of scope helps in reaching an affirmative response to this question. Here, the Quran is discussed in its chronological order and consideration is given to how the themes of the later Medinan surahs relate to the earlier Meccan surahs. Using natural language processing methods and machine learning a succinct overview of how the themes of Medinan surahs contrast with the earlier Meccan surahs of the Quran is provided. Although algorithmic analysis isn’t able to do close reading of the text, this analysis complements and focuses standard analysis of Medinan surahs so that themes can be compared that might otherwise be missed using more traditional approaches.
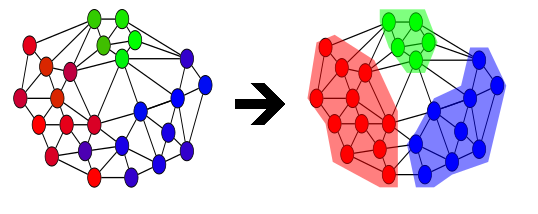
The rise of Digital Humanities has created an intersection between the fields of computing technology and humanities with high potential to provide relevant results in the study of textual data. Graphical analysis of texts made possible with the use computational methods give scholars new ways to observe and interact with text. One important problem in the field lies in finding ways to group documents together by topic. This problem of clustering, finding the best way to group data sets, is a problem with a wide number of varieties depending on the application. One method that’s proven useful in a wide range of domains has been spectral clustering. The algorithm works by constructing a graph of the connections between the data items and then approximating the best way to cut connections in order to separate data items (see below). When dealing with textual data, Markov chains, which model system connections with probabilities, are often used as a rough model of transition frequencies between words and topics in the text. By using spectral clustering on this Markov model it’s possible to separate the vocabulary of the text into groups of words that are frequently used together.
The version of the Quran used for this analysis is Quran in English, by Talal Itani, available online, and downloadable as plaintext. In order to analyze Meccan and Medinan surahs we use the chronological ordering given in How to Read the Qur’an: A New Guide, by Carl Ernst. Although some surahs are a mix of both Meccan and Medinan ayahs, in order to simplify analysis, it was assumed that each surah could be labeled as either strictly Meccan or strictly Medinan. All of the analysis was conducted in python using a variety of external library packages including SciKit which is a machine learning library and NLTK which is a natural language processing library.
The text of the Quran was downloaded as a text file, organized by surah, and then labeled with revelation location. Following this, each group of surahs was broken into word tokens using NLTK. After this, common words are removed from the two texts and then a word count frequency was calculated which returned the number of times the word ‘X’ and then ‘Y’ occurred in the texts for every combination available. After this, a frequency table was constructed that has a probability that the word ‘Y’ follows the word ‘X’. Using SciKit, the texts were spectrally clustered, the best way to group themes is found. Finally, each cluster is matched back to a collection of surahs that have the indicated words in them. Because the correspondence is not one-to-one, we take the largest number of shared surahs for each cluster.
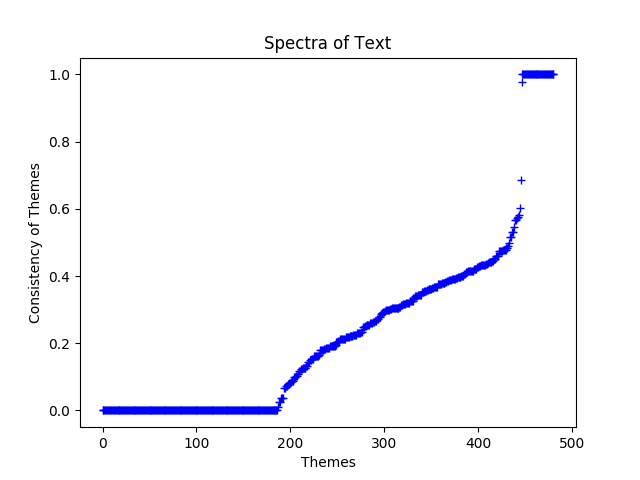
Analyzing the most prominent themes within the Meccan and Medinan portions of the Quran presents a difficult challenge. The reason for this is two-fold. First, by design, the theme clusters discovered by the algorithm are strictly independent from one another. For example, although Allah is obviously a theme in the Quran, it overwhelms everything to such a degree that to not require independence would result in overly repetitive theme clusters. Second, there are limitations to the resolution of spectral analysis. There is a small, but hard, cutoff to how many theme clusters can be generated for a body of text (see below). Therefore, all of the generated themes are reported with the significance measure being more a rough heuristic for homogeneity within the surahs with the theme than a measure of anything more subjective.
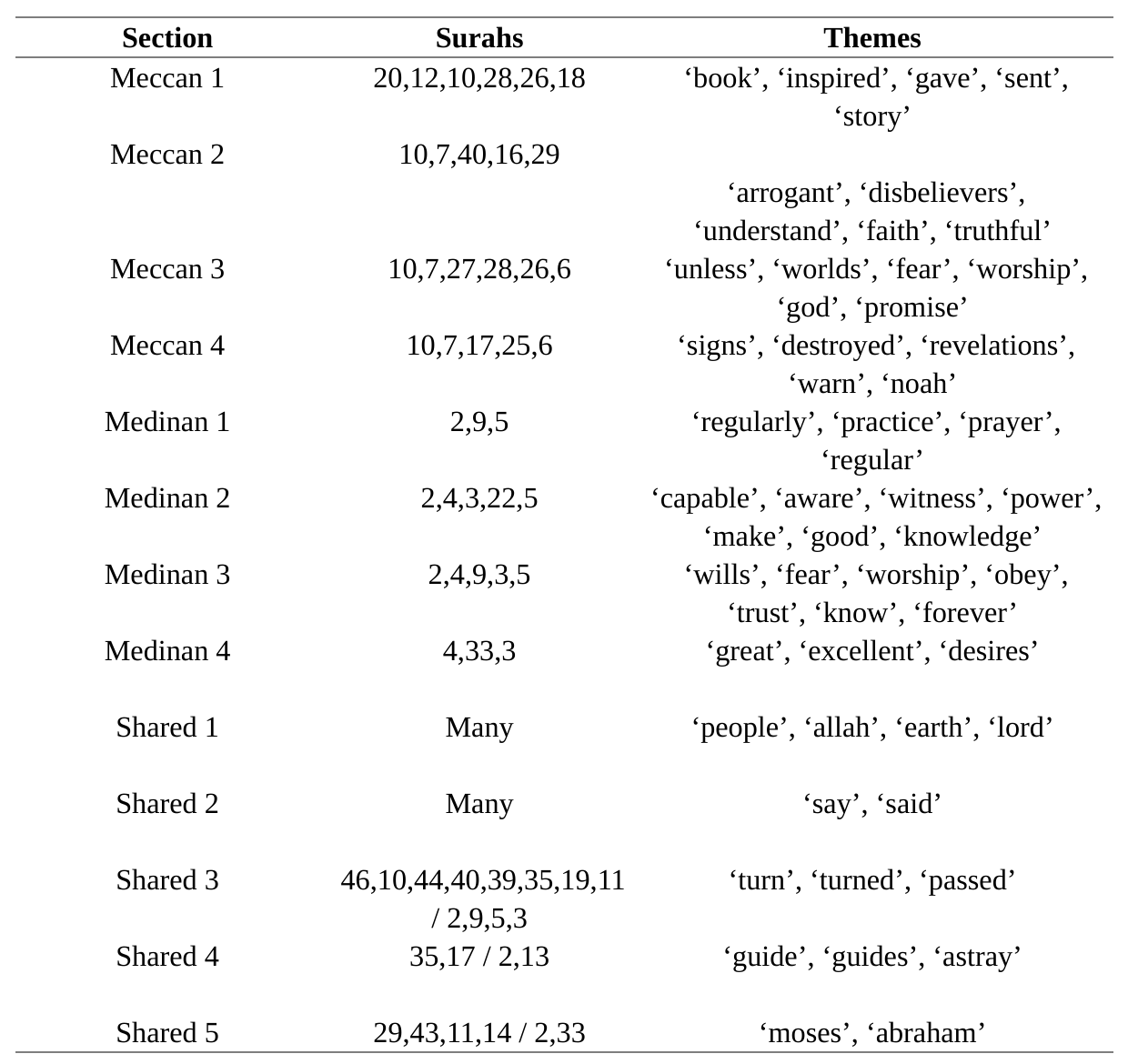
Some of the more interesting themes are the ones that use similar words between the Meccan and Medinan sections. To analyze this, themes were matched on percentage similarity between the sets of words. In general, Meccan and Medinan themes only have about 25% similarity based on this rough metric. Using this finding, a cutoff is imposed on which themes are considered significant. This helps reduce the number of erroneous theme comparisons that would need further inspection. Referring to the table below, the themes that are most strongly represented throughout the Quran are easy to deduce as narrative, god, people, earth, and disbelievers. The algorithm also picks up on frequent mentions of pre-Islamic prophets such as Moses and Abraham. The other themes are subtler to deduce. On the other hand, there are also more words to work with. For example, “turn” and “passed” were grouped together into similar clusters. Without doing a close reading in order to determine the context of these words it’s really rather impossible to deduce what the algorithm was catching onto. Additionally, the words “guide” and “astray” are grouped into the same cluster which also is rather ambiguous to discern meaning from without going to surahs where the words are used.
By separating themes into similar and dissimilar it becomes easier to begin analyzing how themes evolved between the Meccan and Medinan surahs. The differences between similar themes give a baseline for comparisons between Meccan and Medinan surahs because they allow separation of form from content. If the results of the machine analysis are treated as the foundation, then we can directly compare themes of similar content. This separation allows for an analysis of the form, the way in which this content is discussed.
References
Itani, Talal. Quran in English. ClearQuran, 2018. Bird, Steven, Edward Loper and Ewan Klein Natural Language Processing with Python. O’Reilly Media Inc., 2009. Ernst, Carl W. How to Read the Qur’an: A New Guide, with Select Translations. Chapel Hill: University of North Carolina Press, 2011.